
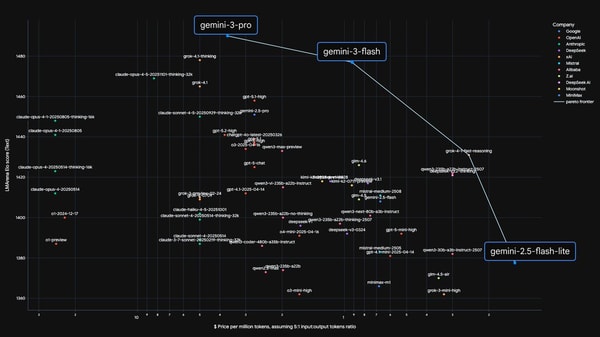
Owning the AI Pareto Frontier — Jeff Dean
Owning the AI Pareto Frontier — Jeff Dean
Owning the AI Pareto Frontier — Jeff Dean
Shownote
Shownote
From rewriting Google’s search stack in the early 2000s to reviving sparse trillion-parameter models and co-designing TPUs with frontier ML research, Jeff Dean has quietly shaped nearly every layer of the modern AI stack. As Chief AI Scientist at Google an...
Highlights
Highlights
Jeff Dean, Google’s Chief AI Scientist and a foundational figure in large-scale AI systems, joins the Latent Space podcast to reflect on decades of innovation—from early neural networks and Google Search infrastructure to Gemini, TPUs, and the evolving Pareto frontier of AI capability and efficiency.
Chapters
Chapters
Introduction: Alessio & Swyx welcome Jeff Dean, chief AI scientist at Google, to the Latent Space podcast
00:00Owning the Pareto Frontier & balancing frontier vs low-latency models
00:30Frontier models vs Flash models + role of distillation
01:31History of distillation and its original motivation
03:52Distillation’s role in modern model scaling
05:09Model hierarchy (Flash, Pro, Ultra) and distillation sources
07:02Flash model economics & wide deployment
07:46Latency importance for complex tasks
08:10Saturation of some tasks and future frontier tasks
09:19On benchmarks, public vs internal
11:26Example long-context benchmarks & limitations
12:53Long-context goals: attending to trillions of tokens
15:01Realistic use cases beyond pure language
16:26Multimodal reasoning and non-text modalities
18:04Importance of vision & motion modalities
19:05Video understanding example (extracting structured info)
20:11Search ranking analogy for LLM retrieval
20:47LLM representations vs keyword search
23:08Early Google search evolution & in-memory index
24:06Design principles for scalable systems
26:47Real-time index updates & recrawl strategies
28:55Classic “Latency numbers every programmer should know”
30:06Cost of memory vs compute and energy emphasis
32:09TPUs & hardware trade-offs for serving models
34:33TPU design decisions & co-design with ML
35:57Adapting model architecture to hardware
38:06Alternatives: energy-based models, speculative decoding
39:50Open research directions: complex workflows, RL
42:21Non-verifiable RL domains & model evaluation
44:56Transition away from symbolic systems toward unified LLMs
46:13Unified models vs specialized ones
47:59Knowledge vs reasoning & retrieval + reasoning
50:38Vertical model specialization & modules
52:24Token count considerations for vertical domains
55:21Low resource languages & contextual learning
56:09Origins: Dean’s early neural network work
59:22AI for coding & human–model interaction styles
1:10:07Importance of crisp specification for coding agents
1:15:52Prediction: personalized models & state retrieval
1:19:23Token-per-second targets (10k+) and reasoning throughput
1:22:36Episode conclusion and thanks
1:23:20Transcript
Transcript
Jeff Dean: Hey, everyone.
Alessio Fanelli: Welcome to the Latent Space Podcast. This is Alessio, founder of Kernel Labs, and I'm joined by Swyx, editor of Latent Space.
Shawn Wang: Hello, hello. We're here in the studio with Jeff Dean, Chief AI Scientist...