
Owning the AI Pareto Frontier — Jeff Dean
Owning the AI Pareto Frontier — Jeff Dean
Owning the AI Pareto Frontier — Jeff Dean
Jeff Dean, Google’s Chief AI Scientist and a foundational figure in large-scale AI systems, joins the Latent Space podcast to reflect on decades of innovation—from early neural networks and Google Search infrastructure to Gemini, TPUs, and the evolving Pareto frontier of AI capability and efficiency.
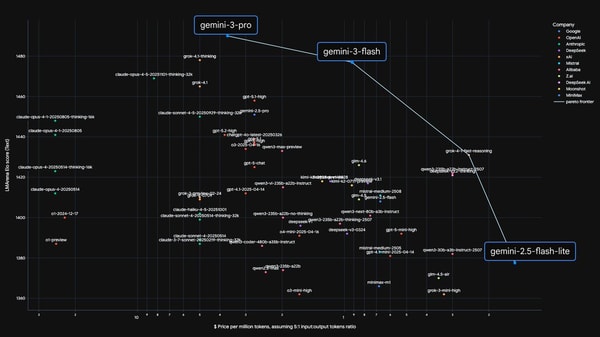
Dean emphasizes that owning the Pareto frontier means simultaneously advancing frontier models (e.g., Gemini Ultra) *and* deploying highly capable, low-latency, cost-efficient models like Flash—enabled by distillation from larger models. He traces distillation’s origins in ensemble compression for image classification and highlights its modern role in making smaller models surpass prior generations. Long-context reasoning isn’t just about scaling attention—it’s about architecting systems that *simulate* access to trillions of tokens via retrieval-augmented, multi-stage narrowing. Energy (picojoules per bit), not FLOPs, is now the true bottleneck, driving hardware-software co-design: TPUs are built 2–6 years ahead of anticipated ML workloads, prioritizing data movement efficiency, sparsity, and low-precision compute. Unified multimodal models like Gemini outperform specialized ones in most cases—but vertical domains (e.g., healthcare) benefit from modular, retrieval-enhanced fine-tuning. Personalized AI, crisp human specification, and ultra-low latency (targeting 10,000+ tokens/sec) are critical for next-generation agentic workflows—where reasoning throughput, not just raw speed, defines utility.
00:04
00:04
Jeff Dean owns the Pareto Frontier
00:30
00:30
Owning the Pareto Frontier requires combining frontier capability and efficiency
01:34
01:34
Distillation is key for making smaller models more capable
03:56
03:56
Distillation emerged to compress an impractical 50-model ensemble into a single deployable model
05:10
05:10
Distillation allows using a smaller model with a large training dataset, getting logits from a larger model to guide the smaller one
07:02
07:02
Flash models serve about 50 trillion tokens due to their economic efficiency
07:51
07:51
The Flash model is very economical, being used in Gmail, YouTube, and search products in AI mode. It's not only more affordable but also has lower latency.
08:17
08:17
Low-latency systems like Flash are crucial for serving models with long-context attention and sparse architectures
09:20
09:20
As models become more capable, users ask them to perform more complex tasks, necessitating more powerful models
11:26
11:26
Once a benchmark reaches 95%, focusing on it yields diminishing returns due to achieved capability or data leakage
12:53
12:53
Single-needle benchmarks are saturating for context lengths up to 128k or 256k
15:08
15:08
Giving the illusion of attending to trillions of tokens would be amazing and have many uses, like accessing the internet, YouTube, and personal data
16:28
16:28
Gemini processes non-human modalities like LiDAR, X-rays, MRIs, and genomics
18:05
18:05
Vision can encode text and incorporate audio
19:08
19:08
Gemini is the only native video understanding model available and uses it for YouTube
20:16
20:16
Google must build an AI search mode broader than human searches
20:51
20:51
An LLM-based system will attend to trillions of tokens but narrow down to a small subset of relevant documents
23:10
23:10
LLMs enable getting the topic rather than relying on explicit words
24:08
24:08
One copy of the index could fit in memory across 1200 machines, enabling semantic query expansion before LLMs
26:47
26:47
A good principle is to design for a 5–10 times scale, as a 100-fold increase may require a different design
28:55
28:55
Jeff Dean's 'Latency Numbers Every Programmer Should Know' originated from real-world infrastructure challenges at Google
30:06
30:06
Every AI programmer should know key system metrics like cache miss times, disk access times, and network round-trip times
32:13
32:13
Moving data across the chip can be 1000 times more expensive than matrix multiplication
34:33
34:33
HBM access is orders of magnitude more expensive and slower than SRAM access on TPUs
35:57
35:57
Chip design takes time and has a long lifetime, so predicting ML computations 2–6 years ahead is crucial
38:06
38:06
Low-precision training saves energy on chips, measured in picojoules per bit
39:50
39:50
Analog-based computing offers low-power benefits but faces digital-analog conversion challenges
42:32
42:32
Applying RL in non-verifiable domains remains a fundamental challenge for reliable AI
44:56
44:56
There has been a significant improvement in models' capabilities, like in mathematics, over the past year and a half
46:13
46:13
Humans may have a neural-net-like distributed representation in their heads, and we're emulating real-brain processes in neural-net-based models
47:59
47:59
It's unclear whether knowledge and reasoning can be cleanly separated during model distillation
50:38
50:38
Combining retrieval with reasoning and multiple-stage interaction makes the model more capable
52:29
52:29
Vertical models can enrich data distributions for specific verticals like healthcare and robotics
55:24
55:24
Healthcare organizations want to train models on their own data
56:10
56:10
Fusing language and image models enables accurate labeling of novel images
1:05:12
1:05:12
Jeff Dean wrote a memo calling Google's fragmented 'Brain Market Place' compute quotas 'stupid' and advocated for unified training
1:10:07
1:10:07
Managing coding agents is like managing a team of interns
1:18:52
1:18:52
Three fast model calls with human alignment may outperform one large, long-written prompt in latency-sensitive contexts
1:19:30
1:19:30
Low latency is essential for responsive user interactions
1:22:36
1:22:36
Generating code at 10,000 tokens per second with chain of thought reasoning would yield better-quality code due to embedded reasoning.
1:23:20
1:23:20
Thank you for the fun and for having me